Acknowledgments
This project would not have been possible without the help of these roasters:Introduction
In the coffee industry, ensuring the quality of roasted coffee beans is crucial. Currently, this process is mostly done by hand, which can be slow, inconsistent, and labour-intensive. Manual inspection not only takes a lot of time but also varies from person to person, making it difficult to maintain consistent quality. This is particularly challenging given the Specialty Coffee Association (SCA) requirements, which set high standards for defect-free beans to achieve specialty status. Automating this quality control process can make it faster, more reliable, and consistent. This project tackles the problem by evaluating different image recognition algorithms to identify defects in roasted coffee beans.
Dataset
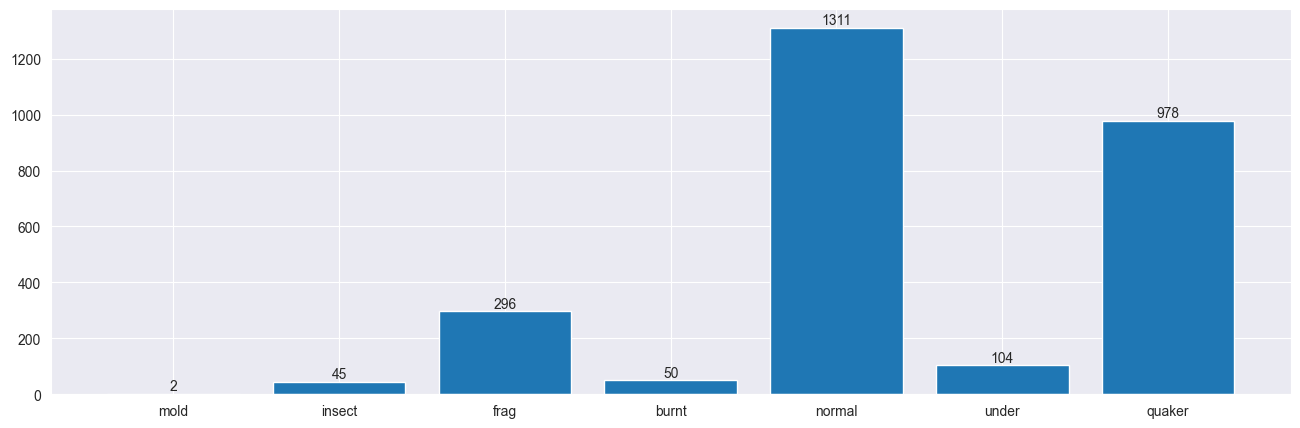
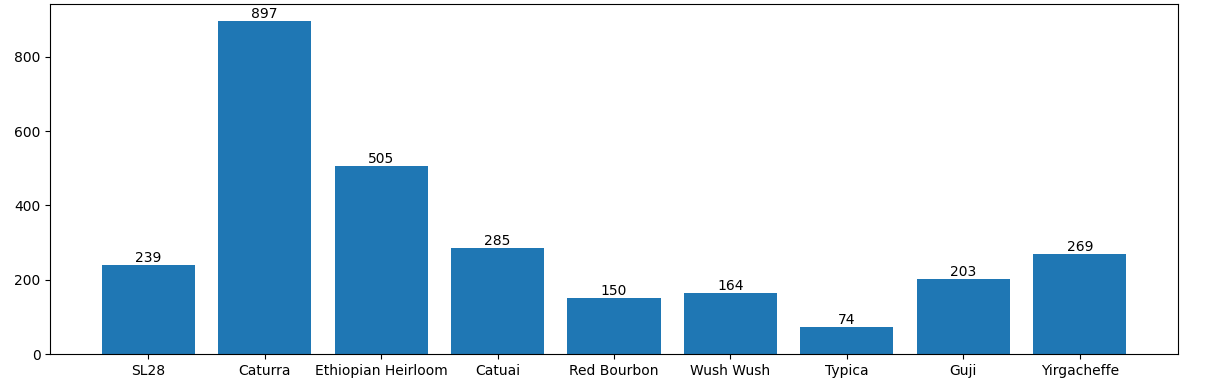
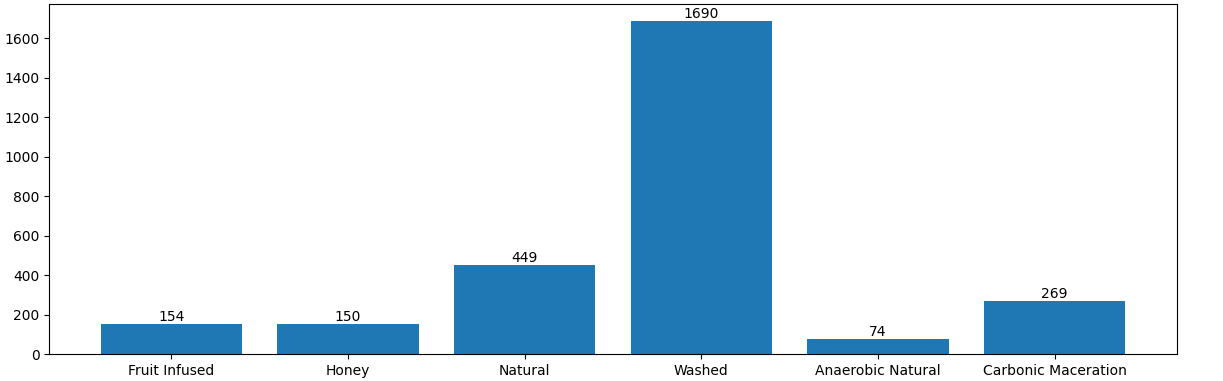
For this project, a special dataset of coffee bean images was created. These images were carefully prepared to help the computer recognize defects more easily. Each image was resized to a standard size of 400x400 pixels, making sure important details like texture were preserved. The dataset included images with both natural backgrounds and pure white backgrounds to see how different settings might affect the results.
Implementation
Several different image classification algorithms were tested to see which one could best identify defects in the coffee beans:- KNN-based Classifier: This algorithm used a special method called the Canberra distance metric and worked with color histograms to simplify the images.
- MobileNet V2: This model was trained from scratch specifically for this task.
- Pre-trained MobileNet: This model had already been trained on a large set of general images (the ImageNet dataset) before being fine-tuned for coffee beans.
- 50-layer ResNet: Another model pre-trained on the ImageNet dataset, known for its depth and ability to handle complex image recognition tasks.
Results
The performance of these models varied:
- The KNN-based classifier achieved an accuracy of 79.7%.
- The MobileNet V2, trained from scratch, reached 84% accuracy.
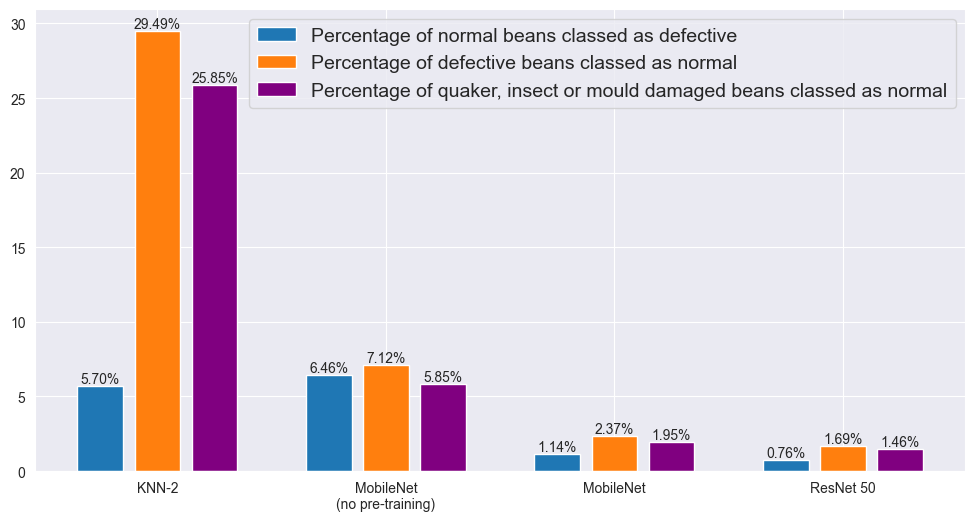
- The Pre-trained MobileNet was the most impressive, with an accuracy of95%.
- The 50-layer ResNet also achieved 95% accuracy but was slower than MobileNet in making predictions.
The pre-trained MobileNet model was particularly notable for its balance of speed and accuracy, making it ideal for real-time applications. It excelled at identifying normal beans with very few mistakes, though it had a slightly higher error rate for defective beans. The ResNet model, while equally accurate, was better suited for batch analysis due to its slower prediction time.